

The Online Retailer Accidentally Leaked How They Define Keyword Relevance In the Process
Online entrepreneurs are generally familiar with the concept of keyword relevance. After all, relevance is what drives the results of any search engine. Google looks to present the most relevant information for a search query. Amazon looks to deliver the most relevant listings.
But what is relevance, exactly?


Get Our Internal Amazon Listing Optimization Operating System HERE 👇
In the context of search, relevance is the term that represents the most appropriate result. For example, if you are searching for a garlic press on Amazon, a relevant result would be a garlic press, as opposed to a yoga mat.
Looking deeper, you’ll find many software tools in the space that attempt to score or weight relevance based on the number of competing products that rank similarly for the same term. This is a somewhat sneaky way to hack Amazon’s relevance engine; rather than try to deconstruct how Amazon defines relevance, this looks to simply use their relevance results as an indicator.
So, it’s clear that what relevance is can be complex in the Amazon context. The more important question then is, why is it important?
What Relevance Means To Amazon Sellers
Relevance is important for Amazon sellers because it is the number one driving factor in keyword rank. In fact, there are only two main factors; relevance and customer status (customer trust score). And relevance is the more heavily weighted of the two.
Relevance consists of a number of elements:
- On-page activity
- Time on-page
- Customer behavior
- Purchase intent actions
- Sales and sales history/velocity
- SEO and keyword density
- Etc. and more
That combined with the customer status, which is an element outside of keyword relevance and beyond the control of the seller or algorithm, creates the mechanism which sorts listings on a browse page on Amazon.
This is why relevance is such an important topic. Understanding what impacts relevance will always be important to Amazon sellers as it literally determines where listings are placed in rank for searched terms.
And while determining relevance based on results (like popular software services do) is incredibly helpful, it doesn’t beat knowing how Amazon actually defines relevance themselves. That knowledge is powerful for any seller looking to rank, optimize, and scale their brand on the platform.
But how can we possibly know how Amazon defines relevance?
After all, Amazon is notoriously secretive about their algorithms. While data was released to the public in the now famous presentation The Joy of Ranking Products, even it only defined how the algorithms work, but not how variables are defined.
However, through some old-fashioned detective work and internet sleuthing, we’ve uncovered how Amazon defines relevance. This information comes directly from Amazon themselves as well.
Machine Learned, Human Verified
By now we all understand that Amazon’s algorithms for relevance and rank are machine learning algorithms. Be that as it may, they can only be as “smart” as the historical data that trains them (and the scientists that develop them).
As such, it is important for Amazon to use human intelligence to test the accuracy of the machine. In The Joy of Ranking Products it was already pointed out that back in 2016 part of the system that defined relevance for a newly categorized product (that didn’t have any historical data) was utilizing customer complaints. Amazon has evolved their approach since those primitive methods.
One such way to leverage human minds to cross-check the intelligence of machines in the context of keyword relevance is by employing micro-workers. Micro-workers are freelance workers all across the globe that do online tasks in exchange for compensation.
The use of micro-workers was confirmed by being referenced (as “crowd workers”) in a paper featured on Amazon.science in 2020. However we were able to witness the act ourselves. A now-deleted work task was published to Toloka, a popular online task assignment website by Russian internet services company Yandex.
This work task asked for micro-workers to search the Amazon website for various keywords and note whether listing results were relevant to the query based on Amazon’s criteria. In order for the micro-worker to know what Amazon’s criteria was, they had to be briefly trained (and quizzed) on how Amazon defines relevance.
Going through this training we were able to capture screenshots that illuminated definitions of various steps of relevance.
Amazon Defines Relevance Training Human Checkers
Here is each page of the relevance-training exercise that Amazon administered in order to have humans check the work of their algorithms:
Page 1 – defining exact match.
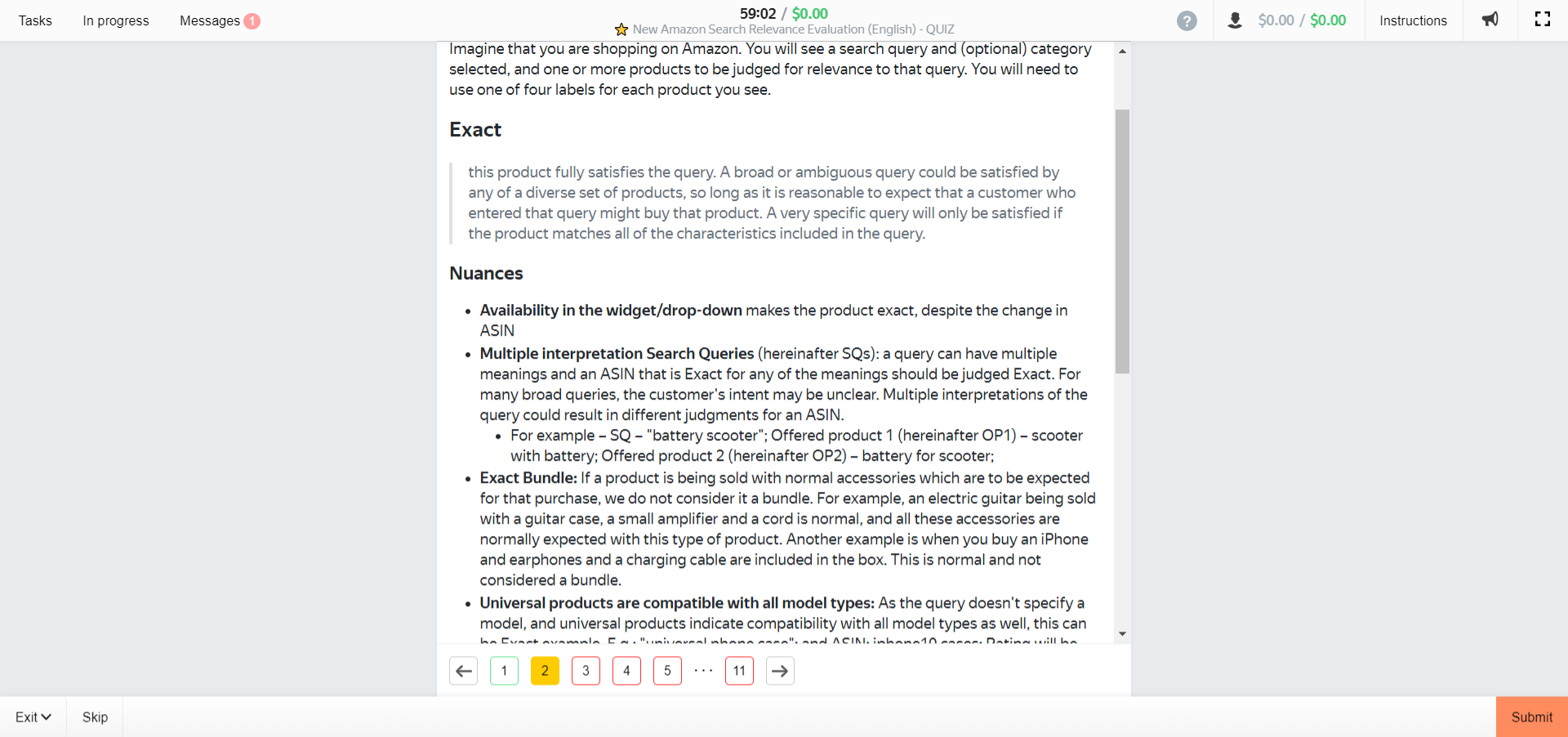
Exact = fully satisfies query.
Page 2 – defining substitute matches.
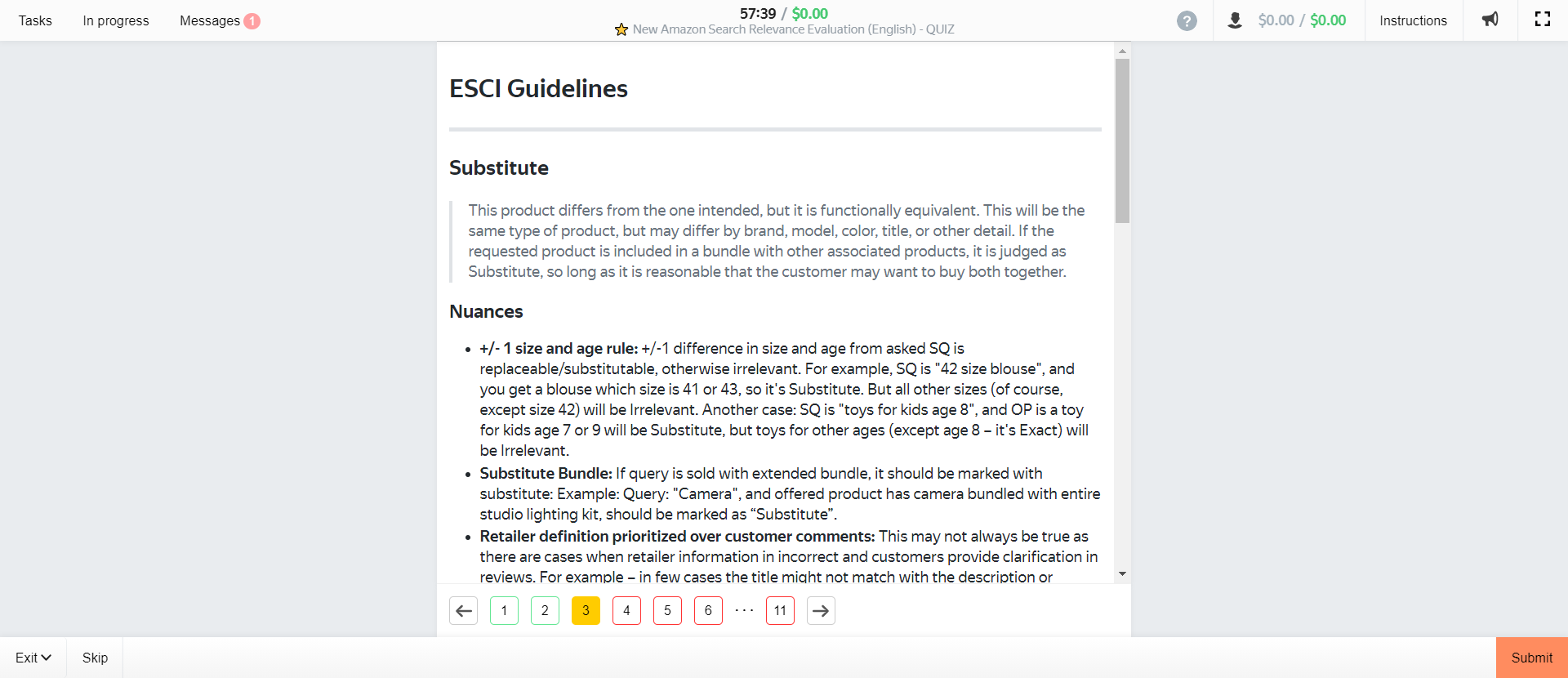
Substitute = differs from intended product but result is functionally equivalent.
Page 3 – defining complement matches.
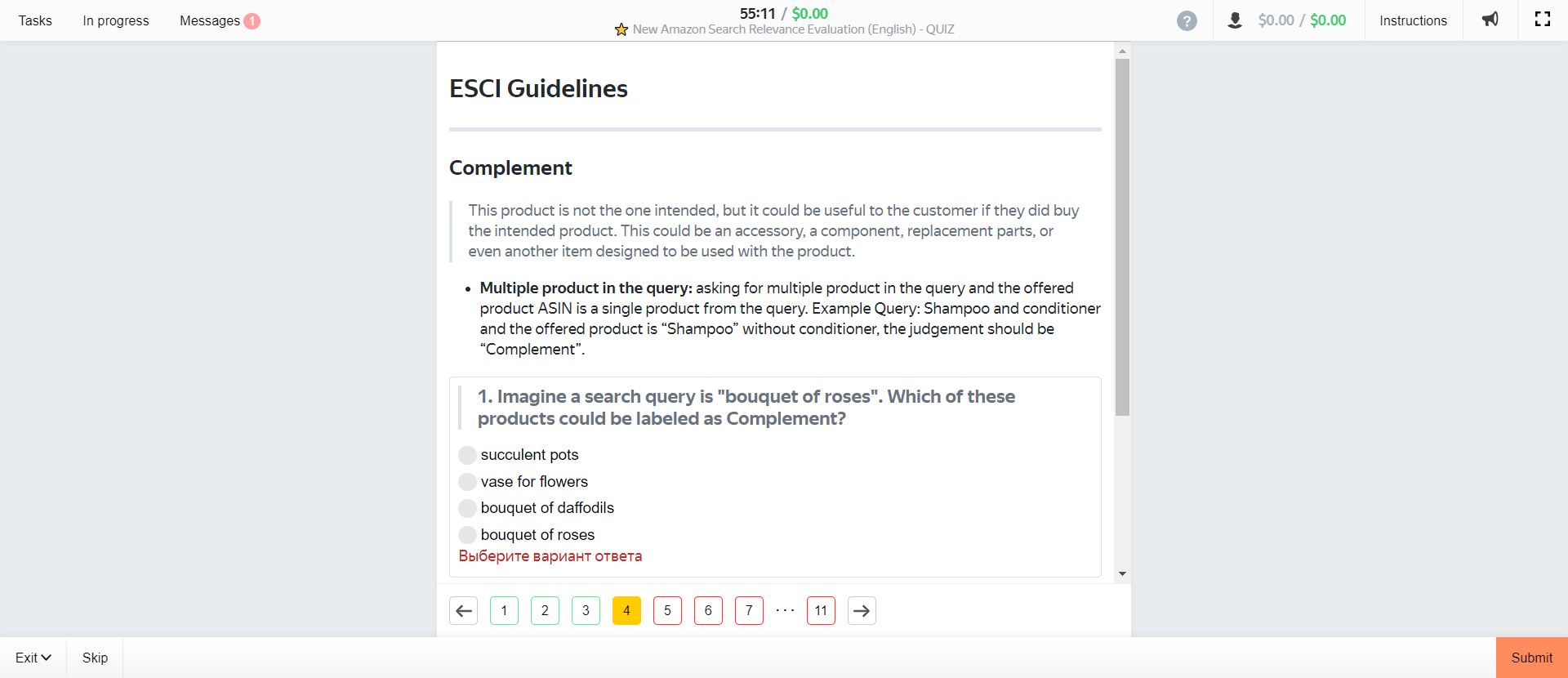
Complement = differs from intended product but could still be useful to customer.
Page 4 – defining irrelevant matches.

Irrelevant = does not satisfy a reasonable understanding of the intent of the customer.
Page 5 – defining unjudgeable matches.

Unjudgeable = query either cannot be understood or the product lacks enough information (i.e. description details are missing).
Those are the most important part of the training as they go over how Amazon defines and categorizes various levels of relevance. For completeness, however, we’ll post the remaining pages (which mainly cover items not sold, misspellings, or other unique circumstances) here:

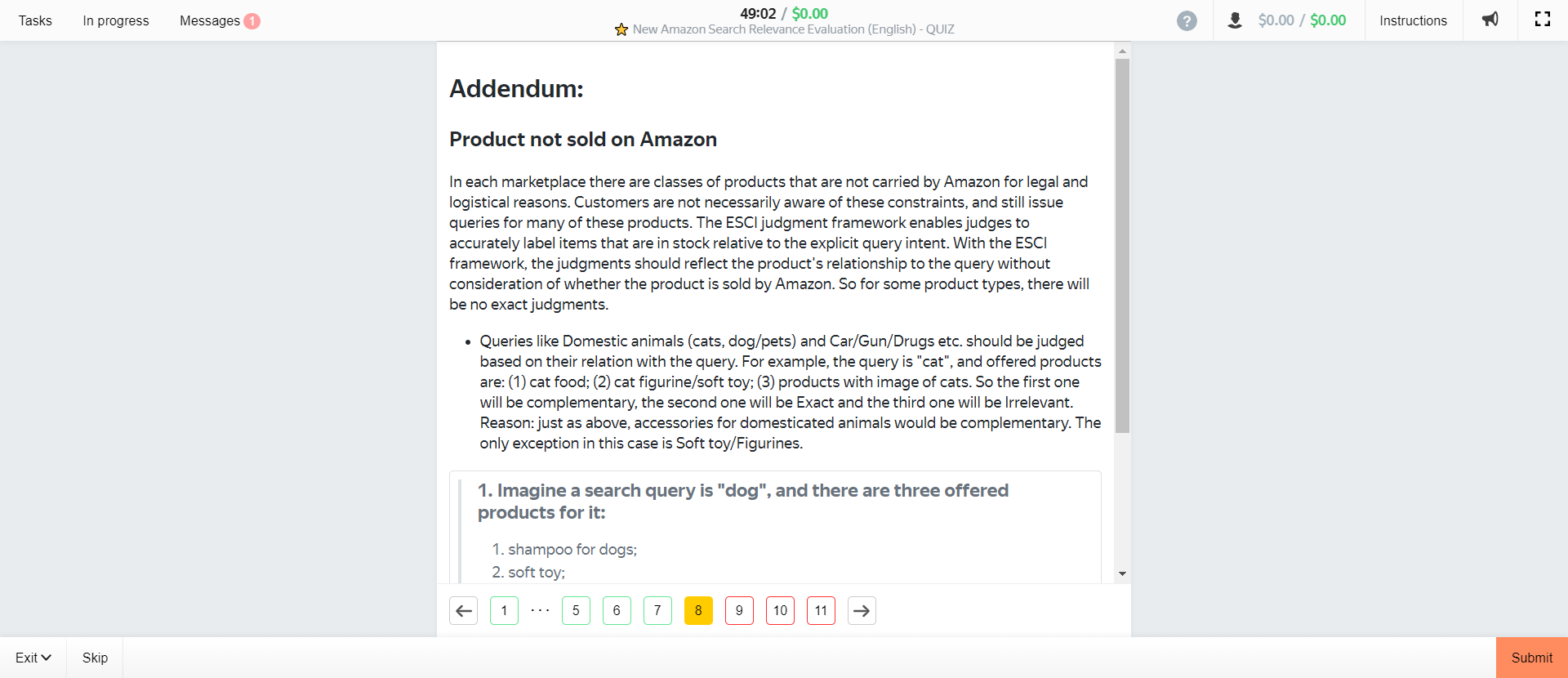
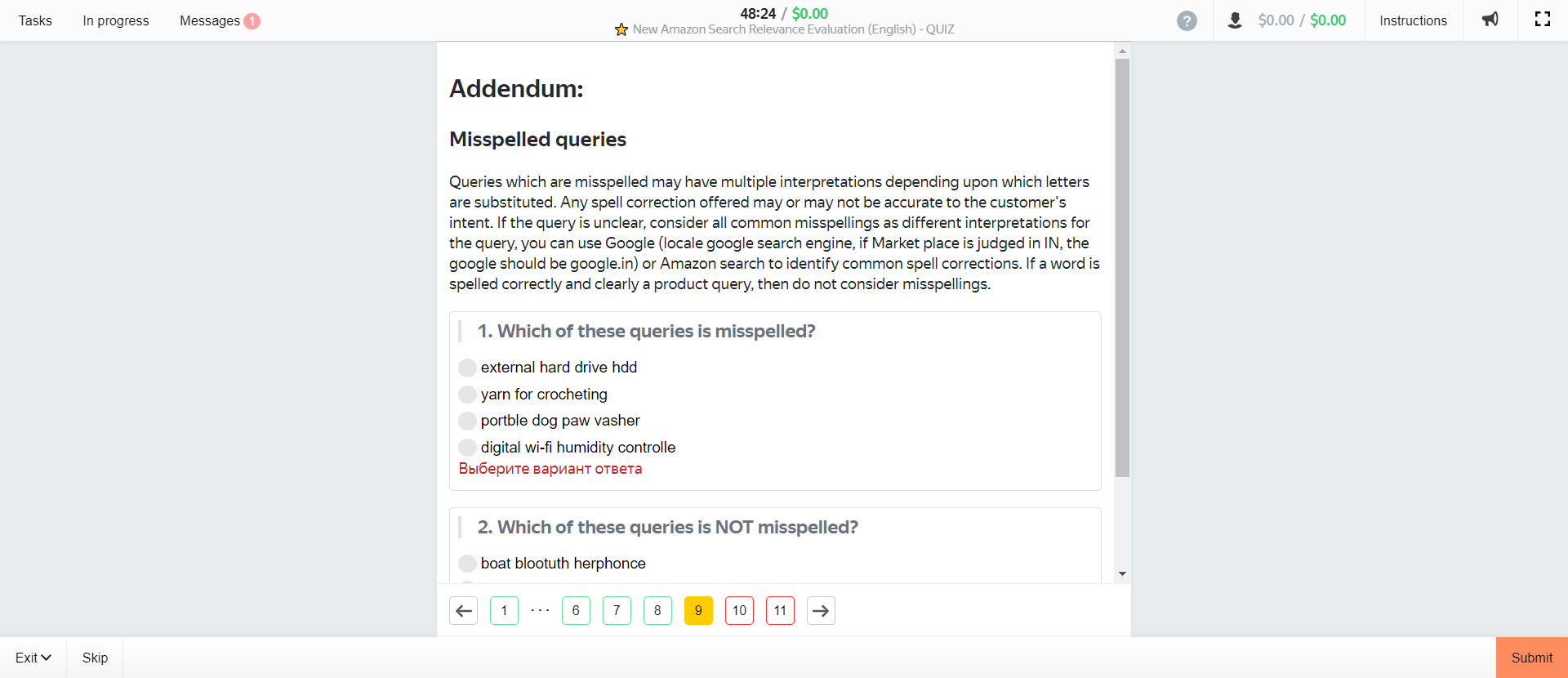
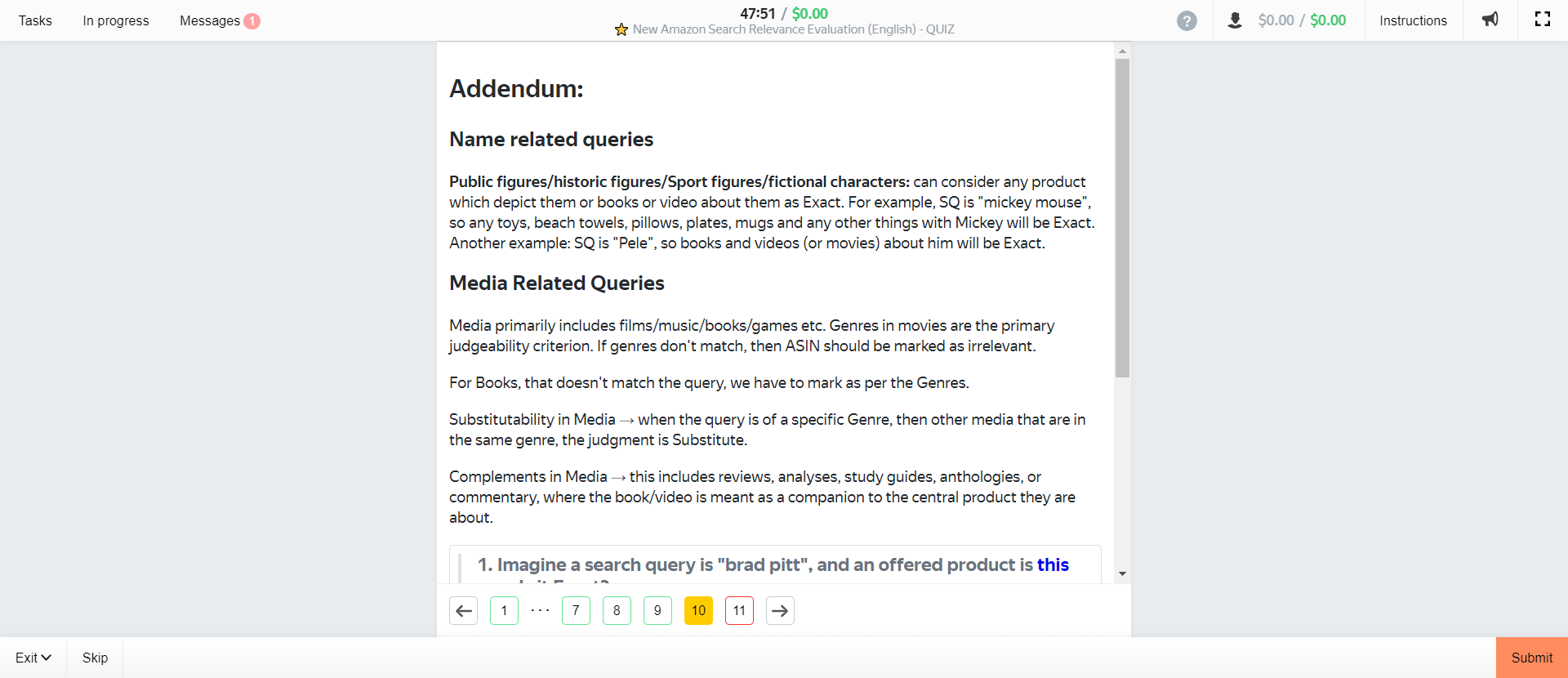
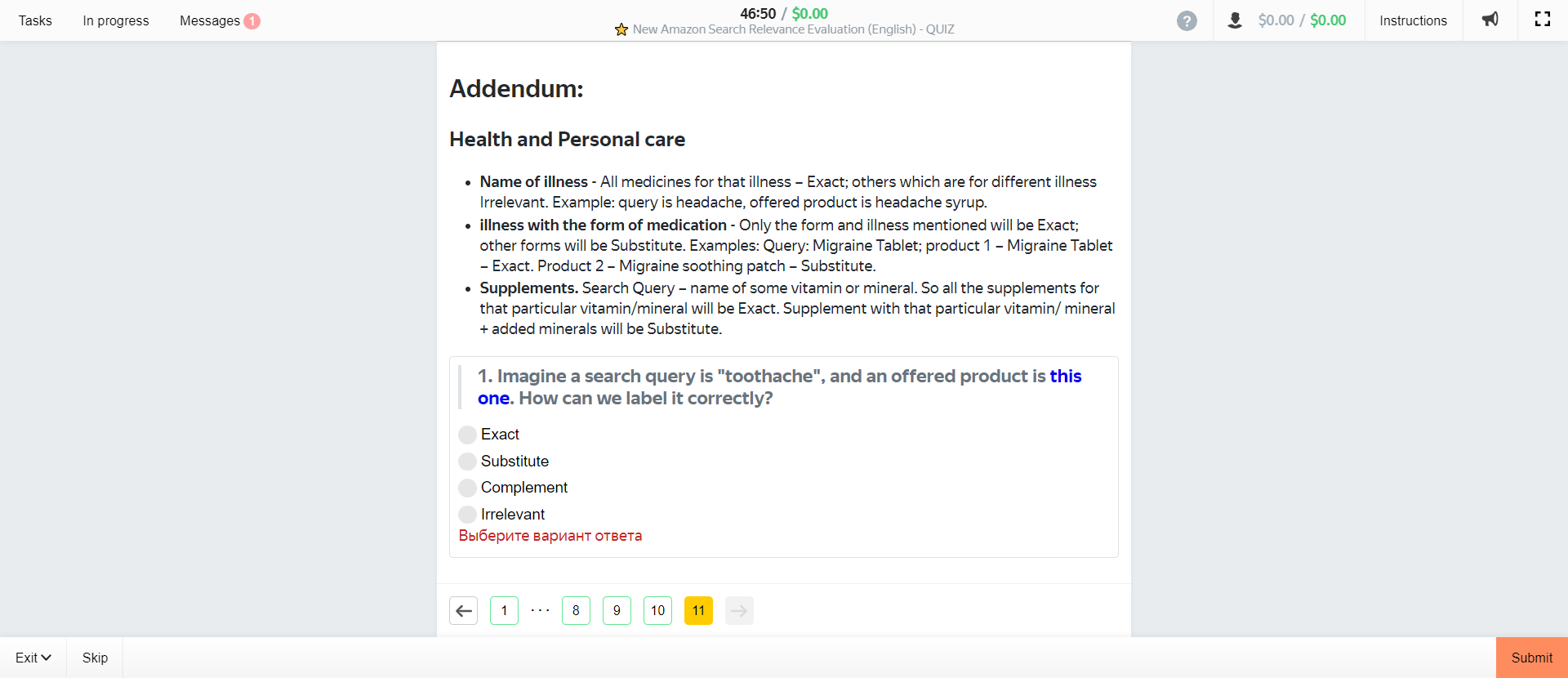
How Amazon Defines Relevance
As we can see in the micro-worker training, Amazon puts search results into four categories of relevance:
- Exact
- Substitute
- Complement
- Irrelevant
We’ll define each separately and then discuss why Amazon has this category.
Exact
An exact match from query to product listing is precisely what it sounds like. This category undoubtedly gets the highest amount of weight in ranking as this represents what a customer is looking for. More often than not, exact matches will dominate the bulk of search page results.
Substitute
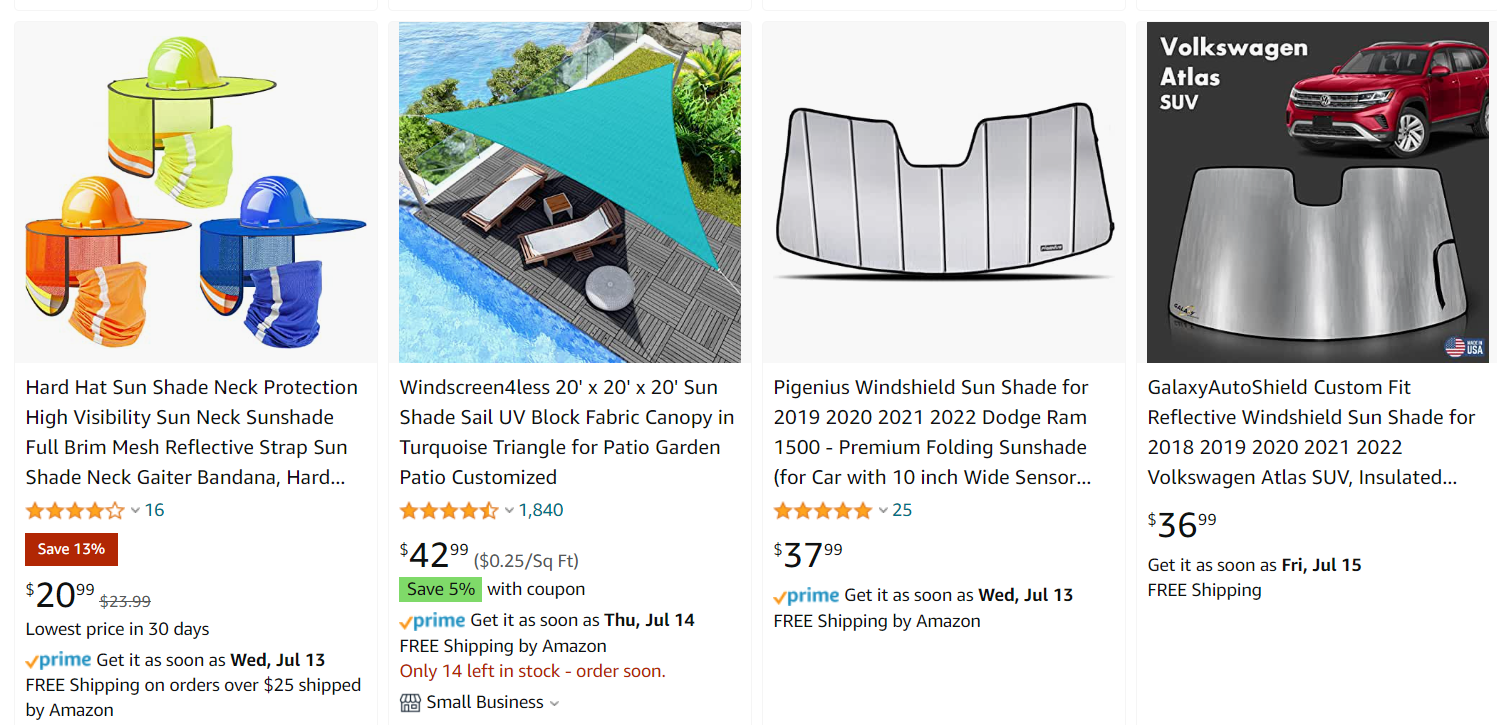
Substitutes are an important aspect of relevant search page results too. First, some terms are vague, overly broad, or may even lack decent product representation. Second, Amazon wants to cover as many intentions as possible for any query. As such, in an effort to ensure shopping customers are always finding what they are looking for, Amazon offers functionally equivalent products that technically fit an exact relevance match for different keywords.
In the below example, when the term “sun shade” was searched, most results were devices that block the sun for porches and cars. However, this substitute listing for a hat with a built in shade was also included.
Complement
Complement matches give Amazon the opportunity to continue to offer the wide array of options on their platform. By matching customer behavior profiles this allows different additional products to be included in a search, which can lead to increased basket size and more shopping. A complement match product is one that could still be useful to a customer searching for a different product.
The complement match option also offers great opportunity to advertisers. Many keywords will not get impressions in PPC if the product is not deemed relevant at all. However, many products have a wider range of relevance through the complement match.
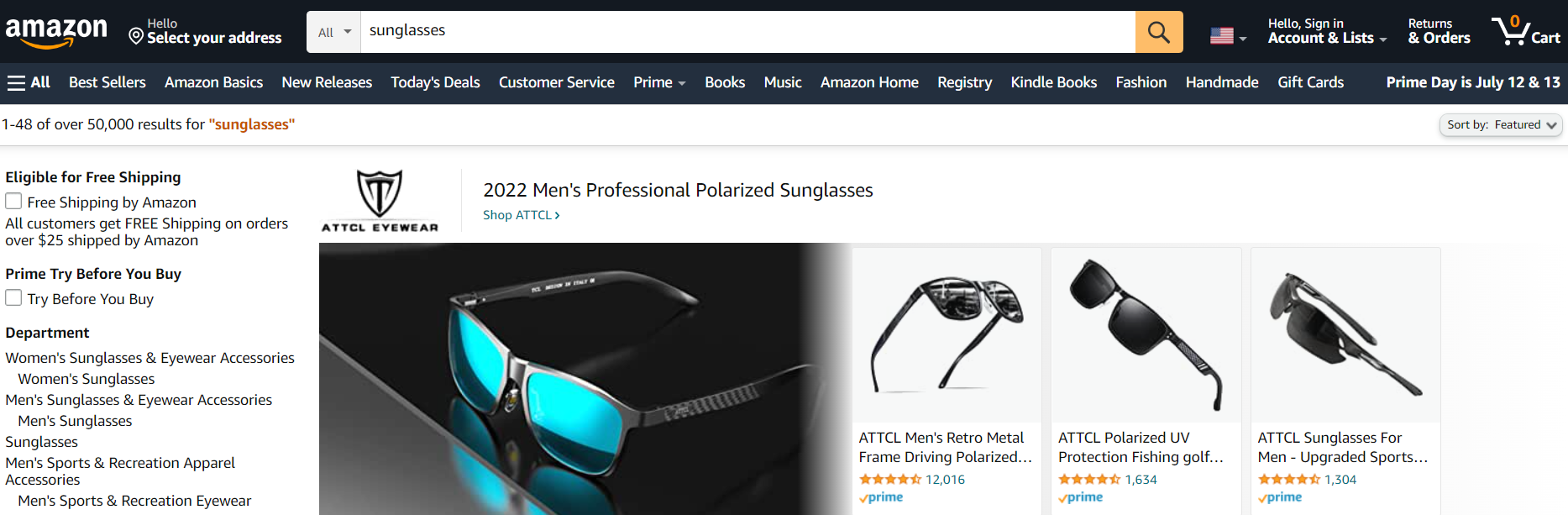
A great illustration of this is in a search for “sunglasses” the returned result of “eyeglass soft cases.”

Irrelevant
Just as exact matches indicate search results that match the query exactly, irrelevant results are deemed entirely not relevant. Now, one may think that the reason Amazon employs humans to go back and check search results is to ensure that irrelevant results are being eliminated.
Interestingly that isn’t always the case. Amazon actually purposefully includes irrelevant results (typically toward the bottom of search result pages) in an effort to remain consistent with its promise to offer everything from A to Z.
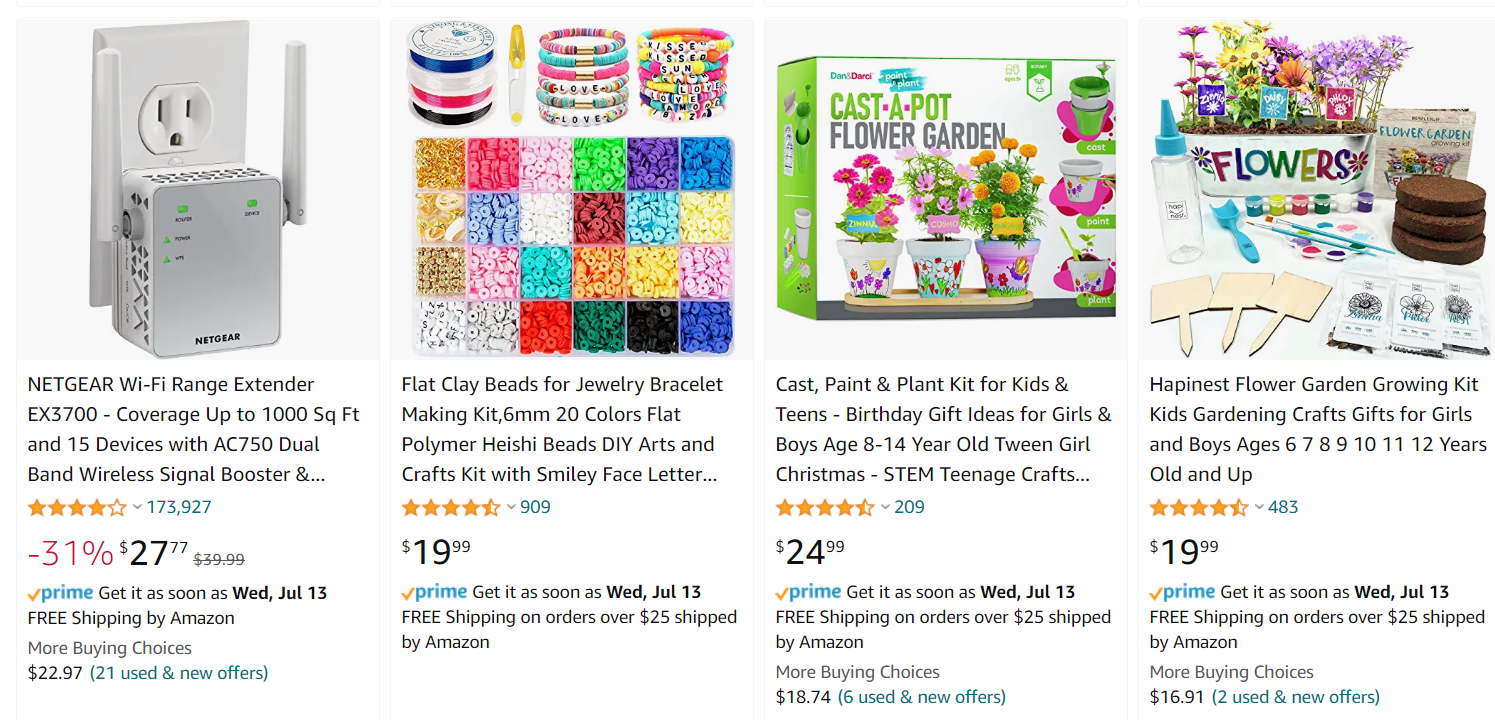
A terrific example of this might be the search “gift for 8 year old girl” resulting in a wifi-extender. Arguably it is difficult to build a case on how such a product is relevant here.
How Can Sellers Use This Information?
The million-dollar question is, how can sellers use this information to gain an advantage?
Well, knowing how Amazon defines and categorizes relevance will allow sellers to predict where listings may organically rank, how difficult it might be to rank for a keyword, what type of impressions to expect in PPC campaigns, and much more.
Basically, this helps sellers predict costs and efforts more accurately in their pursuit to dominate their category.
Is the keyword you are targeting in your rank campaign considered an exact match, or a substitute? Can you target complement keywords in PPC successfully? Which keywords you are paying for traffic to may be considered irrelevant entirely?
This knowledge is precisely the element necessary to make data-informed decisions.